業務責任者
AI が作るデータを業務 record にする
確認する問い
調査メモ、分類、候補、変更案を一時出力ではなく再利用する必要があるか。
見る証拠
record、source、reason、reviewer、採用率、再調査時間。
判断材料
AI output が後続業務に残るなら、DB と audit を同時に設計する。

AI-native database MCP
AI が自律的に table を作り、データを投入し、schema を変え、必要なら rollback できる AI ネイティブな database harness です。
Adoption Review Packet
機能説明だけでは社内説明に進めません。業務責任者、情シス、 セキュリティ、管理部門がそれぞれ確認する問い、見る証拠、判断材料を分けます。
業務責任者
調査メモ、分類、候補、変更案を一時出力ではなく再利用する必要があるか。
record、source、reason、reviewer、採用率、再調査時間。
AI output が後続業務に残るなら、DB と audit を同時に設計する。
セキュリティ / 法務
AI が作った table / column / migration を誰が承認し、どう戻すか決まっているか。
migration purpose、actor、rollback status、destructive change の拒否履歴。
変更理由と rollback が示せるなら、AI-created data を本番候補にできる。
情シス / platform
sandbox、staging、production、trusted agent、read-only agent の境界が明確か。
environment、permission、query limit、schema diff、test result。
探索と本番を分けたまま agent に DB 操作を渡せるなら、platform risk を抑えられる。
管理部門 / 管理者
DB だけでなく agent 定義、実行履歴、waiting_input も判断に必要か。
agent run、data lineage、保存期間、監査提出先、追加 workflow。
run governance が必要なら DB の後に Agent Foundry を検討する。
Problem
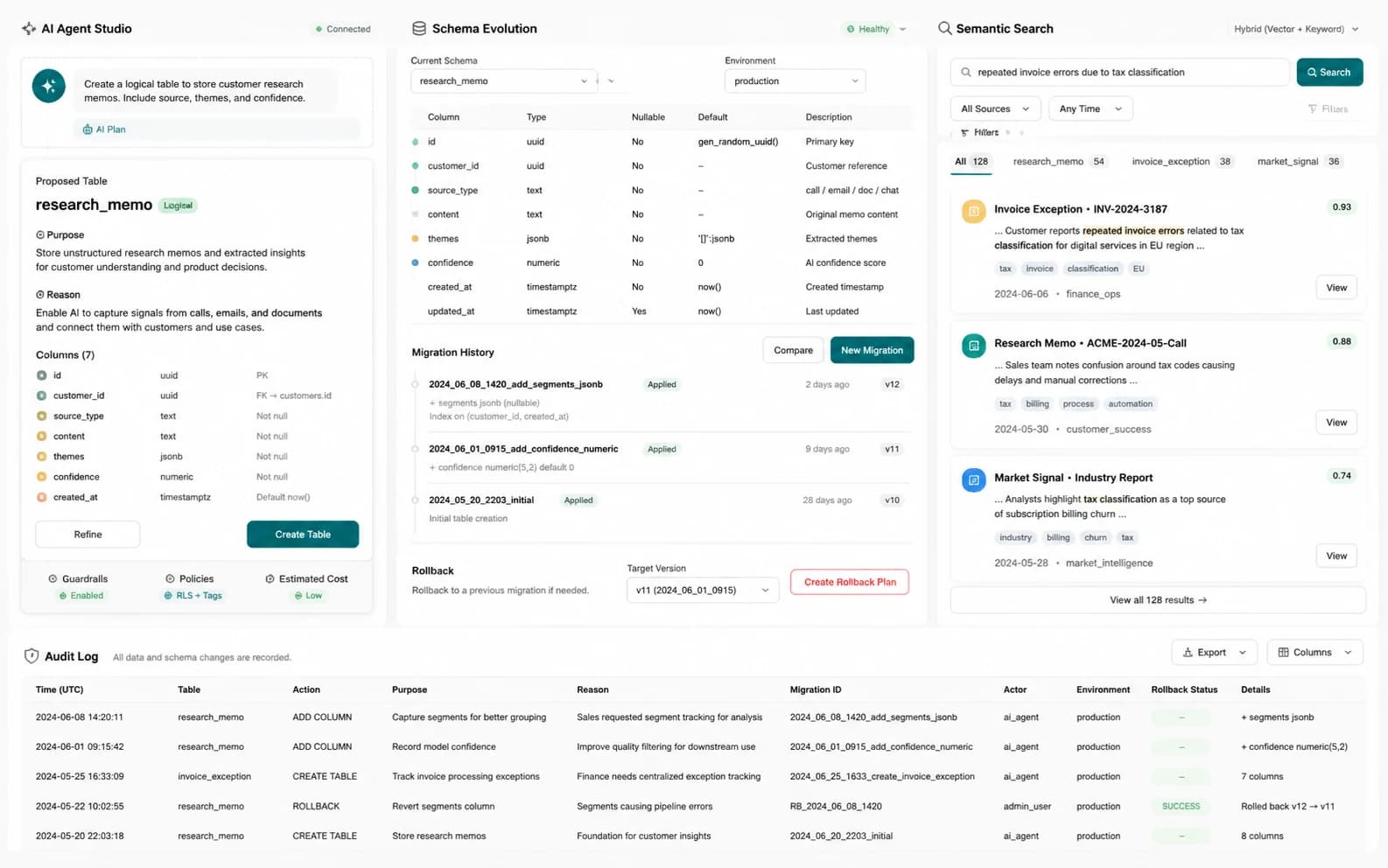
従来は人間が schema を決め、migration を書いてから AI が query します。しかし調査や業務自動化では、AI が問題理解に合わせてデータモデルを変えられることが重要です。viyv DB はその変更理由を DB 自身に残します。
DB Memory & Schema Playbook
DB の価値は AI が table を作れることだけではありません。AI が作る調査メモ、例外分類、業務記録に purpose / reason を付け、schema 変更、semantic search、rollback まで含めて利用前の evidence にします。
Research / Product
市場調査、顧客ヒアリング、競合メモがチャットや個人メモに残り、次の AI session や別担当者が同じ調査をやり直している。
purpose が空の table、reason がない schema 変更、不要な PII 保存、tenant 外検索を拒否する。
table purpose、alter reason、migration history、semantic search 結果、後続 agent が参照した record を確認する。
調査のやり直しを減らし、AI が作った知識を説明可能な社内メモリとして残せることが選ぶ理由になる。
Finance Ops
請求書の税区分、支払先、入金消込の例外判断が spreadsheet と個人メモに散り、翌月も同じ例外を調べ直している。
金額や支払先の更新は DB 側では実行せず、Browser / 承認 workflow に戻す。schema 権限は trusted agent に限定する。
例外分類の再利用回数、判断理由の record、schema 変更理由、rollback できた migration を検証で示す。
Finance には再調査時間、監査担当には判断理由と変更履歴、管理部門には本番運用時の権限分離を提示できる。
Data / Platform
AI にデータモデルを触らせたいが、誤った column 追加、不要 table、意味の薄い migration が残ることを恐れて検証が止まる。
production での destructive change、reason のない drop、system table 変更、row limit を超える query を止める。
誤 column 追加から rollback までの流れ、migration id、rollback status、戻した後の query 結果を見せる。
AI に探索的な schema 進化を任せても、失敗時に戻せる証拠があれば、platform とデータ責任者のレビューに進める。
Concrete Scenarios
ただの機能一覧ではなく、担当者、現在の詰まり、viyv を入れた後の流れ、統制が発火する場所まで具体化します。
AI に記憶を持たせたいが、最初から人間が schema を決めると、実際の会話や業務データに合わせて変えづらい。
AI がデータモデルを作り始めても、なぜその table を作ったかが DB に残るため、後から人間がレビューできます。
市場調査や競合分析では、途中で新しい分類軸や指標が見つかるたびに migration 依頼が発生する。
探索的なデータ設計を止めず、失敗しても戻せる形で AI に schema 進化を任せられます。
問い合わせ履歴、対応メモ、監査メモが別々の表にあり、キーワード完全一致では欲しい記録に届かない。
AI が作ったデータを、そのまま AI が意味検索できる knowledge base にできます。
Capabilities
PostgreSQL 上の system table と JSONB により、DDL lock に依存せず logical table を作成・変更します。
create_table、alter_table、drop_table の意図を履歴に残し、未来の AI セッションと人間レビューが理解できる状態にします。
get_schema、create_table、query、insert、update、import_csv、semantic_search、rollback_migration などを提供します。
multi-tenant remote mode、JWKS/HS256 認証、行数制限、クエリ timeout、rate limit で本番組み込みを支えます。
Use Cases
ユーザー嗜好、過去の判断、顧客メモなどを AI が適切な table として作成し、後続セッションで参照できます。
市場調査や競合分析中に新しい signal を発見したら、その場で table を作り、列を追加し、検索可能にします。
CSV から table を自動作成し、embedding を有効化すればテーブル横断の semantic search を使えます。
Implementation Path
最初は read / data で運用し、schema 権限は trusted agent や開発環境に限定すると導入しやすくなります。
table 名の再掲ではなく、役割・主要フィールド・変更動機を書かせることで、未来の AI session が理解できます。
AI が誤って table や column を変えた時に、migration_info から戻せることを実演します。
Product Validation Brief
製品詳細を読んだ後は、相談時に何を決めるかまで落とします。最初の workflow、 持ち込む情報、通す統制、判断材料を 1 枚にできます。
Start
空の DB から AI が業務メモリを作る を起点に、担当者、入力、AI の役割、人間に戻す判断を 1 つずつ決める。
Bring
AI アプリ開発者 / 業務自動化チーム が使う画面 / tool / data、現在の作業時間、AI に任せたい作業、止めたい操作を整理する。
Control
purpose 必須 / system table 保護 / access-level read/data/schema / migration_info
Decision
AI 活用のたびに人間が migration を書く bottleneck を減らす。AI が作った DB の意図と変更履歴を説明可能にする。この変化を検証の証拠で説明できれば、Team / Enterprise の検討へ進む。
Pilot Design
検証は「触ってみる」だけでは足りません。対象業務、必要な統制、成功条件、次の展開先を 1 枚で説明できる状態にしてから始めます。
Start Workflow
AI に記憶を持たせたいが、最初から人間が schema を決めると、実際の会話や業務データに合わせて変えづらい。
Control Scope
Success Evidence
Adoption Signals
AI にメモリや業務データを持たせたいが、人間 migration がボトルネック
調査・分析の途中で schema が何度も変わる
AI が作った table の意図を後から説明したい
キーワード検索ではなく意味検索で業務履歴を探したい
Product Selection Board
viyv は suite なので、最初の製品選びが重要です。必要な状態、まだ別製品から始めるべき状態、 利用前に集める証拠、次に足す製品を 1 枚で確認できます。
Choose
Start Elsewhere
Proof
Next Product
Adoption Decision
製品の機能だけでは判断に進めません。どの状態なら必要なか、まだ早いか、検証 で何を集めるかを明確にします。
Buy When
Not Yet
Proof
Stakeholder Answers
どの作業時間を削るか、どの判断を人間に残すかを、具体シナリオと成功指標で説明できます。
認可、接続方式、監査、既存システムとの境界を architecture と implementation path で整理できます。
AI に渡る情報、保存されるログ、人間承認が必要な操作を control scope として切り出せます。
Buyer Review Questions
製品詳細の最後に、役割ごとの確認事項を整理します。業務、platform、 セキュリティ、管理部門がそれぞれ何を聞き、どの証拠で判断するかを分けます。
業務責任者
空の DB から AI が業務メモリを作る を起点に、現在の詰まりを AI が get_schema で空 DB を確認、purpose を書いて preferences や customers などの logical table を作成、insert / query_table で使いながら、必要な列を後から追加 という流れに変えます。
AI 活用のたびに人間が migration を書く bottleneck を減らす / AI が作った DB の意図と変更履歴を説明可能にする
情シス / platform
MCP server: Claude Code などから npx で起動し PostgreSQL に接続 / Logical layer: table 定義、columns、rows、migrations を system table に保持 / Search: pgvector と multilingual embedding で意味検索を追加
access-level を用途ごとに分ける / purpose / reason の品質を review する
セキュリティ / 法務
purpose 必須 / system table 保護 / access-level read/data/schema / migration_info
空の DB から AI が業務メモリを作る を対象に、担当者・入力・出力・人間判断を 1 枚で説明できる / 最初に通す統制: purpose 必須 / system table 保護 / access-level read/data/schema
管理部門 / 管理者
AI にメモリや業務データを持たせたいが、人間 migration がボトルネック 状態なら、1 workflow の検証で fit を確認します。
空の DB から AI が業務メモリを作る を対象に、担当者・入力・出力・人間判断を 1 枚で説明できる / 最初に通す統制: purpose 必須 / system table 保護 / access-level read/data/schema / 運用後に期待する変化: AI 活用のたびに人間が migration を書く bottleneck を減らす / AI が作った DB の意図と変更履歴を説明可能にする
30-Day Rollout
最初から全社展開を狙わず、1 つの業務・1 つの統制・1 つの成功条件に絞って、継続利用すべきかを判断します。
空の DB から AI が業務メモリを作る を起点に、担当者、入力、出力、人間が判断する地点を決めます。
最初は read / data で運用し、schema 権限は trusted agent や開発環境に限定すると導入しやすくなります。
拒否理由、承認待ち、tool 呼び出し、schema 変更、実行 event など、判断材料に使う証跡を集めます。
AI 活用のたびに人間が migration を書く bottleneck を減らす かを確認し、部門追加、connector 追加、Enterprise 要件を整理します。
Buyer FAQ
置き換えません。Claude、GPT、Cursor、社内 agent などの前後に置き、接続・統制・監査の境界を追加します。
対象業務、利用する画面または tool、許可したい操作、止めたい操作、レビューしたいログを 1 つずつ決めれば始められます。
AI に渡る範囲、認可条件、人間承認、masking、audit metadata、失効・rollback の運用を、製品ごとの検証証跡として提示します。
Business Outcomes
Architecture
Claude Code などから npx で起動し PostgreSQL に接続
table 定義、columns、rows、migrations を system table に保持
pgvector と multilingual embedding で意味検索を追加